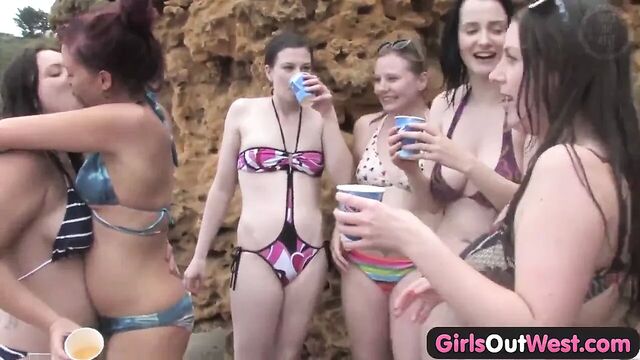新規登録
ログイン
検索
日本語
English
Deutsch
Français
Italiano
Español
Português
Русский
Türkçe
中文
ホームページ
新着
視聴率の一番高い
人気
ジャンル
チャネル
モデル
トップのジャンル
Sri Lankan
487
Eating Pussy
9355
Bangladeshi
614
Indian
5300
Taxi
348
Cowgirl
11003
Venezuelan
204
Dad
1330
For Women
5015
Solo
774
Rough Sex
5001
Big Cock
29457
Colombian
957
Tight Pussy
7686
Couple
1061
Doggy Style
14299
Titty Fucking
1762
Big Ass
27745
Gaping
1673
もっと読み込む...
トップのチャネル
NIKS INDIAN
94
Pussbebe2103
47
Your Priya
77
Tharumini_Official
20
Teste de Fudelidade
96
Desi Bhabhi Ki Chudai
32
11up Movies
23
もっと読み込む...
トップモデル
Priya Tiwari
20
Poonam Pandey
72
Mia Khalifa
105
Sunny Leone
56
Alyx Star
62
Elisa Sanches
56
Nadia Ali
42
もっと読み込む...
視聴中の XXX ビデオとセックス ムービー
6:51
MyDirtyHobby - Chubby teen gets banged!
98%
2.0M
29:32
Wife's husband real pleasure
98%
138K
13:55
Girls Out West - Nasty lesbian orgy at the beach
99%
1.9M
8:53
Devinn does her best
96%
11K
11:31
Liya Silver Desperately Wants Her Busy Hubby Alberto
98%
263K
2:35
Hard labor and whipping - the fate of a slave
98%
78K
26:44
Mature at Public Beach Sex before Rough Anal with Stranger in Hotel
100%
10K
10:21
TINY4K, Cosplay Creampie Assassin With Redhead Nala Brooks
97%
23K
1:13
Jessica Chastain - ''Lawless'' 01
90%
18K
25:20
Devin Trez, Jay Alexander & Roxas Caelum
100%
111K
7:03
Busty brunette dominatrix tells her man to titty-fuck her
98%
566K
8:53
MyDirtyHobby - Busty teen quits college to become a pornstar
98%
62K
1:59
Anna Paquin Nude Lesbo Sex Scene On ScandalPlanet.Com
98%
498K
7:30
DevilsGangbangs Skinny Slut Anal Creampied
95%
354K
8:42
Petite Roommate Fucks My Face Until SHE CUMS HARD In My Mouth - Standing PUSSY FAC...
100%
181K
新しいポルノ動画
新着の
人気の
トップの
8:00
DOWN FOR BBC - Amber Rayne BBC Blowbang Feeds Dick - Petite Deepthroat
0%
93
30:57
Jennifer White Dddddcccccc
0%
97
28:13
Alexandra Sivroskya, Croft Se Coge A Su Entrenador Personal Sin Que Los Vea Su Esposo
0%
105
7:05
Time For Anal With Latina Wifes Round Booty - Crystal Rush
0%
95
11:07
NGENTOT LAGI COY
0%
172
9:58
Tall And Slender 18 Yr Old Sucks A Fat Cock
100%
118
28:55
Lexi Belle Eyes Of An Angel
0%
118
32:58
Fat Ass Asian Loves BBC - Jade Kush
0%
125
29:49
Melody Marks Spank Monster
0%
132
27:59
Carol Gostosa No Carnaval
0%
108
8:01
FANTASY GIRL PASS - Carmella Bing Party Girl Gets DP Anal - Foxi Di
0%
76
15:47
Twins Threesome
0%
142
5:26
Mumpung Dirumah Sepi,di Kontolin Ayang
0%
132
23:04
Lillianette Gets Double Teamed
0%
79
29:04
Valentina Nappi Outdoor
0%
89
21:48
Czech Streets 129 - Nina Roca
0%
89
25:19
Eva Notty Real Good Bitch
0%
124
30:23
Abigaiil Morris Sneaky Spa XXX
0%
162
16:38
Fighters Scene 02
0%
122
7:05
Busty Hazel Ass Fucked By Teacher At Home - Hazel Moore
0%
108
24:38
Two Huge Tits Milf Myamaretto Amaretto Hammer X Kim Velez - Kim Triple X
0%
131
6:13
වැටකෙයි පදුරැ අස්සේ..sri Lanakan Sex Capal
0%
167
11:06
Nani Mami
0%
118
31:14
Mommy, You're Hard Briana Banderas
0%
155
30:16
Guy Bangs Harem Of Women
0%
129
前へ
最初の
1
2
3
4
5
6
7
8
9
...
最後の
次へ
sexs
fucks
milfed
boob tit
small boobs
fucking
babeds
big boobs
tits tits tits
asshole closeup
cocks
vagina fuck
sex
milf a
ass
ass tit
analed
blowjobs
mobiles
cock
全てタグを見る